Research is not for the disorganised: anyone who wants results has to plan – and that is something TU Wien has always done. Now, however, the university is moving to the next level. By the end of 2026, the Rectorate will shift its research strategy to a data-driven approach. Thomas Haschka, AI consultant for EuroCC Austria, opens an external URL in a new window, is part of the research team from the “Knowledge Graph Lab” together with Emanuel Sallinger, Eleonora Laurenza, Alessandro Pesare, Roxana Dogaru, Max Tiessler as well as Moritz Staudinger and Tatiana Beliaeva in Allan Hanbury's team that uses AI-based methods such as knowledge graphs and LLMs to analyse TU Wien’s past research output and lay the groundwork for future strategic decisions.
Around 4,600 people conduct research at TU Wien across 51 institutes. They publish roughly 700 articles each year in about 50 journals – an immense amount of data. This data now serves, alongside project submissions and individual research profiles, as the foundation for restructuring the research matrix introduced in 2009. The name of the project within which this is taking place is Research Spheres.
But why? What is the point of Research Spheres?
“Every university in Austria defined research priorities and related thematic areas years ago. Since research is a dynamic process, it is now time to revise this system,” says Elisabeth Schludermann, Senior Advisor for Research and project lead. “The existing research matrix is highly static and does not reflect many current topics – such as AI or high-performance computing. The project aims to develop approaches and tools that can represent research at TU Wien in a way that is appropriate and meaningful for its various audiences – data-driven and evidence-based.”
Thomas Haschka is part of the project team, an AI specialist at TU Wien’s dataLAB and advisor to the EuroCC Austria team on questions of artificial intelligence. The AI tool he developed is essential to the project, as it makes it possible to analyse publication output in great detail and group it based on similarities between abstracts. This generates fresh impulses for potential research topics, which can then be further developed and help strengthen the research community.
30,000 abstracts as fuel for the AI
What exactly did Thomas Haschka do? Thanks to the EuroCC project, he was one of the first in Austria to gain access to the new MUSICA high-performance computer. With the help of 80 GPUs from the supercomputer’s total of 272 GPU nodes and 168 CPU nodes, he was able to programme an algorithm and deploy an associated large language model (LLM).. Without MUSICA’s immense computing power, this part of the project would not have been possible. And even with MUSICA, annotating all research fields from all TU Wien abstracts took three days.
The “fuel” for the LLM consisted of around 30,000 abstracts from published articles and about 2,000 submitted projects (which usually later result in publications). All abstracts were provided by TU Wien’s research information systems unit, specifically from the ReposiTum (TU internal), Scival-Scopus, opens an external URL in a new window and Dimensions databases, opens an external URL in a new window. The project data came from TU-internal databases as well as Dimensions.
Haschka processed these tens of thousands of records, removed duplicates and kept only English texts to provide clean and comparable material for the AI model. He then generated an embedding vector for each abstract – a bit like creating a map where each article appears as a dot. If two articles deal with similar topics, the dots lie close together on this map. Based on these distances, Haschka formed groups – so-called clusters. All articles with related content end up in the same cluster.
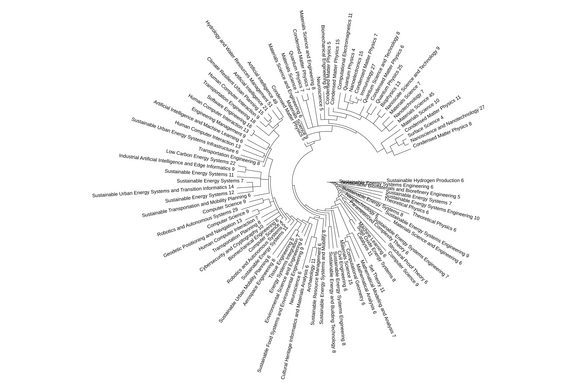
From many clusters to a tree
All these clusters were then arranged hierarchically, like a tree: small groups of closely related articles form branches, which merge into larger limbs until all topics converge at the “trunk”. The closer the thematic similarity between abstracts, the nearer they sit in the tree.
This is where the LLM comes into play. Its role was to find a name for each branch and cluster – a sort of overarching label describing what the articles are about. “Quantum physics”, for instance, or “sustainable materials”, “artificial intelligence” and so on. In the end, every branch has a label. This is crucial for recognising and understanding the various research areas being pursued.