Forschung ist nichts für Chaoten: Wer Ergebnisse will, muss planen – und genau das macht die TU Wien seit jeher. Doch nun geht es ins nächste Level: Bis Ende 2026 stellt das Rektorat seinen Forschungsplan auf einen datenbasierten Ansatz um. Thomas Haschka, KI-Berater bei EuroCC Austria, öffnet eine externe URL in einem neuen Fenster, ist Teil des Forschungsteams aus dem “Knowledge Graph Lab” gemeinsam mit Emanuel Sallinger, Eleonora Laurenza, Alessandro Pesare, Roxana Dogaru, Max Tiessler sowie Moritz Staudinger und Tatiana Beliaeva im Team von Allan Hanbury, das mit KI-basierten Konzepten wie Knowledge Graphs oder LLMs die bisherigen Forschungsleistungen der TU analysiert und somit die Basis für weitere strategische Entscheidungen legt.
An der TU Wien forschen rund 4.600 Menschen an 51 Instituten. Sie publizieren jährlich rund 700 Artikel in rund 50 Journals. Eine unfassbare Menge an Daten. Diese dienen nun, neben den Projekteinwerbungen wie auch den individuellen Forschungsprofilen als Grundlage, die 2009 ins Leben gerufene Forschungsmatrix neu zu strukturieren.
Aber warum eigentlich? Was ist der Sinn von Research Spheres?
„Jede Universität in Österreich hat vor Jahren Forschungsschwerpunkte und die dazugehörigen Themenfelder festgelegt. Nachdem Forschung ein dynamischer Prozess ist, ist es nun Zeit, das System zu überarbeiten“, sagt Elisabeth Schludermann, Senior Advisor für Forschung und Projektverantwortliche. „Die bisherige Forschungsmatrix ist sehr statisch aufgebaut und hat viele aktuelle Themen wie zum Beispiel KI, High Performance Computing noch nicht abgebildet. In dem Projekt sollen Ansätze und Tools entwickelt werden, die Forschung an der TU Wien entsprechend und gut für die jeweiligen Zielgruppen abzubilden – datengetrieben und evidenzbasiert.“
Thomas Haschka ist Teil des Projektteams, KI-Profi beim dataLAB, öffnet eine externe URL in einem neuen Fenster der TU Wien sowie Berater des EuroCC-Austria-Team in Fragen rund um Künstliche Intelligenz. Sein entwickeltes KI-Tool ist essentieller Bestandteil des Projekts, da er die Publikationsleistungen nun bis ins Detail analysiert und anhand Ähnlichkeiten in Abstracts in neue Gruppierungen gesetzt hat. So entstehen neue Impulse für potentielle Forschungsthemen, die dann weiter aufgegriffen werden und zum Community-Building beitragen.
30.000 Abstracts als Futter für die KI
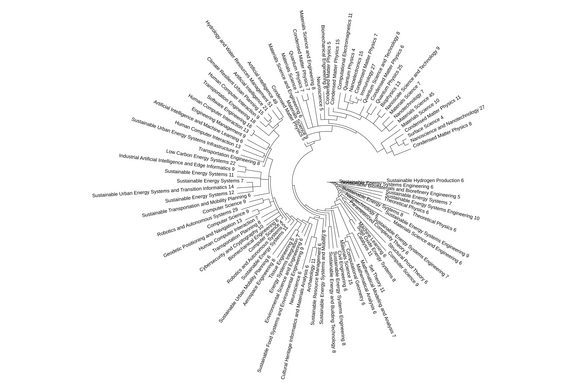
Was hat Thomas Haschka konkret gemacht? Dank des EuroCC-Projekts hat er als einer der ersten in Österreich Zugang zum neuen Hochleistungsrechner MUSICA erhalten. Mit Hilfe von 80 GPUs der der insgesamt 272 GPU- und 168 CPU-Knoten des Supercomputers konnte er einen Algorithmus programmieren und ein dazugehöriges Large Language Model (LLM) einsetzen. Ohne die immense Rechenleistung von MUSICA wäre dieser Projektteil gar nicht möglich gewesen. Und selbst mit MUSICA dauerte das Annotieren aller Forschungsfelder aus allen TU-Wien-Abstracts drei Tage.
Das Futter für das LLM bestand aus etwa 30.000 Abstracts publizierter Artikel und rund 2.000 eingereichten Projekten (aus denen später meist Publikationen werden). Alle Abstracts wurden vom TU-Fachbereich Forschungsinformationssysteme zur Verfügung gestellt; konkret aus den Datenbanken von ReposiTum (TU intern), Scival-Scopus, öffnet eine externe URL in einem neuen Fenster und Dimensions, öffnet eine externe URL in einem neuen Fenster. Die Projektdaten stammen aus TU-internen Datenbanken sowie Dimensions.
Thomas Haschka nahm diese zehntausenden Daten und bereinigte sie, löschte doppelte Einträge und behielt nur englische Texte, um dem KI-Modell sauberes, vergleichbares Material zu liefern. Anschließend ließ er für jeden Abstract einen sogenannten Embedding-Vektor berechnen. Man kann sich das vorstellen wie eine Landkarte, auf der jeder Artikel als Punkt erscheint. Behandeln zwei Artikel ein ähnliches Thema, liegen sie auf dieser Karte nahe zusammen. Auf Basis dieser Abstände hat Haschka Gruppen gebildet; sogenannte Cluster. Alle Artikel, die inhaltlich verwandt sind, landen im selben Cluster.
Aus vielen Clustern wird ein Baum
Dann wurden all diese Cluster hierarchisch angeordnet, wie ein Baum: Kleine Gruppen von eng verwandten Artikeln bilden Zweige, die zu größeren Ästen zusammenlaufen, bis schließlich alle Themen am „Stamm" enden. Je enger also die inhaltliche Verwandtschaft zwischen Abstracts, desto näher liegen sie im Baum zusammen.
Hier kommt das LLM ins Spiel: Sein Job war es, für jeden dieser Äste und Cluster einen Namen zu finden; eine Art Oberbegriff, der beschreibt, worum es in diesen Artikeln geht. „Quantenphysik“ zum Beispiel, oder „nachhaltige Materialien“, „Künstliche Intelligenz“ etc. Am Ende hat jeder Zweig ein Label, einen Namen. Das ist wichtig, um die einzelnen Forschungsbereiche zu (er)kennen, an denen geforscht wird.